
Non è ancora stata ripristinata la versione tedesca del sito Italia.it, disattivata quando si è scoperto che vari toponimi che in italiano hanno anche un significato comune (“capitonym”) erano stati tradotti con nomi comuni tedeschi equivalenti.
Alcuni esempi: Camerino ➝ Garderobe, Cento ➝ Hundert, Chiusi ➝ Geschlossen, Cuneo ➝ Keil, Fermo ➝ Stillstand, Nervi ➝ Nerven, Potenza ➝ Leistung, Prato ➝ Rasen, Salve ➝ Hallo.
Non solo: la traduzione automatica aveva trasformato in parole tedesche anche toponimi che in italiano sono solo nomi propri senza un significato particolare.

In questi esempi Rivisondoli è diventato “revisioni”, Sorradile “sorriso”, Tinnura “acufene”.
Per capire perché sia successo riporto anche qui alcune informazioni sulle parole strane e anomale che a volte si trovano in testi prodotti dalla traduzione automatica, come ad es. freyeria di aria, tazzole, scala di detec, spatulla, cuccioli di frutta e murciolini, viste nei sottotitoli italiani di un video coreano.
Traduzione automatica e “vocabolari”
Innanzitutto va ricordato che i sistemi di traduzione automatica neurale (NMT, Neural Machine Translation), che sono quelli prevalenti, ignorano il significato di quanto stanno traducendo. Grazie all’autoapprendimento identificano regolarità statistiche e ricorrono ad algoritmi e modelli predittivi per produrre le sequenze di parole più probabili in quel particolare contesto. Non credo sia un caso che nelle traduzioni tedesche di italia.it siano stati sbagliati solo i toponimi nei titoli, singole parole isolate, ma non quelli all’interno di testi descrittivi che invece sono stati trattati correttamente come nome propri.
Semplificando al massimo, i sistemi di traduzione automatica vengono addestrati (training) su testi paralleli in lingua 1 e in lingua 2, ad es. inglese L1 e italiano L2, da cui ricavano dei loro “vocabolari” (vocabulary), che però sono incompleti: mancano tutte le parole non presenti nei testi usati per il training.
Va anche considerato che il lessico di ogni lingua è un sistema aperto, in continua evoluzione, e sarebbe impossibile avere “vocabolari” esaustivi. Oltretutto, sia per questioni di spazio richiesto che di tempi di elaborazione, per la traduzione automatica neurale è improduttivo avere “vocabolari” di grandi dimensioni, che devono invece essere il più ridotte possibile.
Parole OOV
Come fa allora la NMT a gestire parole out of vocabulary (OOV) che non ha mai incontrato prima? Un’opzione è lasciarle nella lingua originale, ma il testo tradotto potrebbe risultare incomprensibile. Un’altra opzione è usare “dizionari” di supporto a cui la NMT può attingere per le parole mancanti, soluzione possibile ma per nulla efficiente e soggetta comunque a errori, ad esempio quando non c’è corrispondenza biunivoca tra parole della L1 e della L2 . Si ricorre invece ad altre soluzioni.
Parole e “sottoparole”
Per ottimizzare il processo di traduzione i sistemi di NMT non operano a livello di parole come le intendiamo noi, ma di unità più piccole ottenute con particolari tipi di segmentazione, come ad es. sottoparole (subwords) formate da sequenze di caratteri (n-gram), oppure singoli simboli che rappresentano le sequenze di caratteri più frequenti e che sono ottenuti con particolari algoritmi di compressione.
Da un punto di vista umano solo alcune subword apparirebbero significative, ad es. quelle che corrispondono a morfemi, altre invece non lo sarebbero affatto. I sistemi di NMT invece riescono ad individuare pattern a noi non apparenti, apprenderli e utilizzarli poi nella traduzione.
Questi metodi di segmentazione hanno il vantaggio di ridurre notevolmente le dimensioni dei “vocabolari” e di consentire di gestire adeguatamente le parole OOV, anche sfruttando similarità lessicali tra lingue. Ad esempio, è probabile che una parola inglese inusuale come cynophobia venga resa correttamente in italiano con cinofobia, come farebbe un traduttore umano, perché è composta da elementi formativi neoclassici combinati in base a un modello di composizione ricorrente.
Problemi noti
Sono soluzioni che però possono portare a una serie di errori lessicali tra cui la creazione di parole inesistenti, sia per singole parole che per composti ed espressioni polirematiche, più o meno evidenti e ricorrenti in base alle caratteristiche di ciascuna coppia di lingue.
Nel caso di singole parole, vengono fatti errori di vario tipo:
- parole solo apparentemente ben formate in L2 ma che in realtà non sono usate o hanno un altro significato, come nell’esempio di enogastronomia tradotto in tedesco con *Önogastronomie, descritto da Anna B.: “[in Germania] Öno è usato solo in parole tecniche come Önologe, mentre nella maggior parte dei composti si usa Wein-; Gastronomie invece è un classico falso amico e vuol dire ristorazione”;
- parole che assomigliano a parole L1 ma inesistenti in L2, ad es. dall’inglese *nodoli per noodle, *freyeria per fryer;
- parole inesistenti in L2 ma che assomigliano a parole esistenti o plausibili in L2, ad es. *tappuccio è simile sia a tappo che a cappuccio; *giantina e *murciolini sono del tutto conformi alla struttura delle parole italiane;
- parole non riconducibili né a L1 né a L2, ad es. dal video coreano *toalla e *raissella (le sequenze oa e ai seguite da doppia consonante sono inusuali in italiano), probabilmente una qualche interferenza da altre lingue come spagnolo o francese. Per coppie di lingue inusuali può succedere infatti che il passaggio dalla L1 all’italiano L2 non sia diretto ma avvenga attraverso una terza lingua pivot (ad es. inglese, o francese, o spagnolo), e nel passaggio da una lingua all’altra gli errori si propagano e si amplificano.
Tornando agli esempi iniziali dei toponimi italiani tradotti in tedesco, per noi umani italofoni è ovvio che Rivisondoli, Sorradile, Tinnura ecc. sono nomi propri senza alcun significato comune, ma non per la traduzione automatica che si trova a doverli gestire fuori contesto.
La traduzione automatica non li ha mai incontrati prima e si può ipotizzare che li abbia gestiti come farebbe con i nomi comuni, “interpretandoli” in base alla somiglianza con segmenti di lessico già noto, probabilmente sfruttando anche quanto appreso dal riconoscimento dei refusi. E così Circhio è diventato “cerchio”, Scalea “scale”, Pescarenico “pesca”, Aprica “aprire”, Tagliacozzo “tagliatore di cocco” e così via.
Qui sopra ho semplificato molto, ma chi è interessato all’argomento troverà utili due articoli in inglese che consentono di capire bene meccanismi ed errori, con vari esempi:
- Neural Machine Translation of Rare Words with Subword Units
- View of NMT’s wonderland where people turn into rabbits. A study on the comprehensibility of newly invented words in NMT output
Vedi anche: altri esempi di errori di traduzione di italia.it nei commenti a Open to Meraviglia… and to perplessità
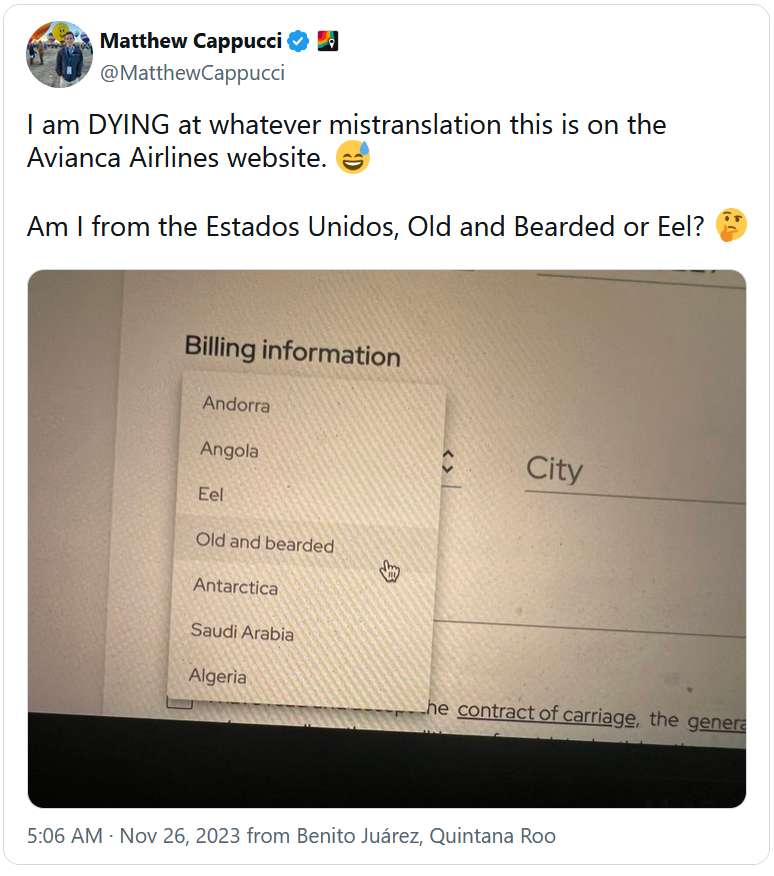
Aggiornamento: esempi analoghi di traduzione automatica di toponimi dallo spagnolo all’inglese nel sito della compagnia aerea colombiana Avianca: Anguilla è diventato Eel (ma in spagnolo l’animale è anguila, con una sola L); si nota anche la traduzione letterale di Antigua y Barbuda in Old and bearded.
Dandandin:
Nell’app “alpha clock” di Sony compare un panorama che mostra il “Grande muro di porcellana”
Licia:
@Dandandin in inglese China è proprio un esempio di capitonym, significato diverso con iniziale maiuscola e minuscola. Mi stupisce comunque che una locuzione come Great Wall of China sia stata tradotta erroneamente, forse non è un errore recente ma di qualche tempo fa quando i motori di traduzione automatica erano molto meno efficienti di quelli odierni?
Enrico:
Molto interessante, grazie.
Anna B.:
Cara Licia,
grazie (anche se dopo qualche mese) per l’approfondimento! Negli articoli mi ha colpita il fatto che non si sia ancora trovata un’altra soluzione tecnologica per rendere le parole mai incontrate prima, malgrado la rapida evoluzione e i grandi investimenti in questo campo. Infatti, se è vero che in certi casi funziona (come nell’esempio di cynophobia che citi), quando si formano parole inesistenti diventa difficile capire il senso delle frasi. I sottotitoli dal coreano avevano proprio un che di surreale …